Mastering Activation Functions in Neural Networks
AfterAcademy Tech
•
06 Dec 2019

In this article, we are going to learn about the Activation function and its types. We are going to cover the following topics:
- What is the Activation function?
- What is a good Activation function?
- Types of Activation functions
- When to use which Activation function in Neural Network
What is the Activation function?
The Activation function is the function that is used to calculate whether the neuron will be activated or not. The above definition might be not so clear so let's understand it with intuition.
Suppose we have to make a project where we need to find out whether the patient's liver is working fine or not. We also have a set of data and by applying linear regression, we came to know that how much liver is working. Now, we apply a function that determines - how much percent of the liver is working, we can declare it to be fine or not. Suppose, we set criteria that function will return fine if the liver is working more than 60% and return damaged if it is working less than 60%. This type of function is called the Activation Function.
From the above example, let's see how the Activation function works. The function activates the output node to be fine when it sees that the liver is working more than 60% and it activates the output node to be damaged if the liver is working less than 60% percent. The Activation function defines the output to a certain range.
What is a good Activation function?
A good Activation function has the following properties:
- Monotonic Function: The activation function should be either entirely non-increasing or non-decreasing. If the activation function isn't monotonic then increasing the neuron's weight might cause it to have less influence on reducing the error of the cost function.
- Differential: The word differential mathematically means the change in y with respect to change in x. The activation function should be differential because we want to calculate the change in error with respect to given weights at the time of gradient descent.
- Quickly Converging: The meaning of quickly converging means that the activation function should fastly reach its desired value. Suppose we want two outputs which are 0 and 1, then we want that the activation function should quickly converge to either 0 or 1.
Types of Activation function
The Activation function is divided into 3 types:
- Binary step Activation function
- Linear Activation function
- Non-Linear Activation function
Binary step Activation function:
In simple words, if the value of the input is negative then the output is zero else the output is 1.
This is the most common activation that comes to our mind if we want to classify the output into two categories. It is more like an if-else condition. Let's look at its graph and function:
f(x)=0 for -infinity<x<=0
f(x)=1 for 0<x<infinity
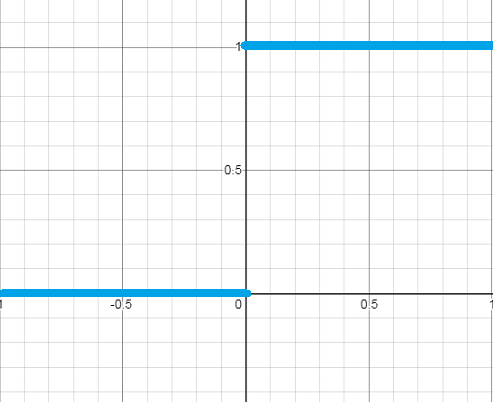
This activation function is only used in binary classification. Otherwise, it is not used due to its discontinuity.
The gradient descent cannot be applied with this activation function because it cannot be differentiated.
Linear Activation function
A linear function is a function that maps to a straight line. It has a simple function with the equation:
f(x)=ax+c where -infinity<x<infity
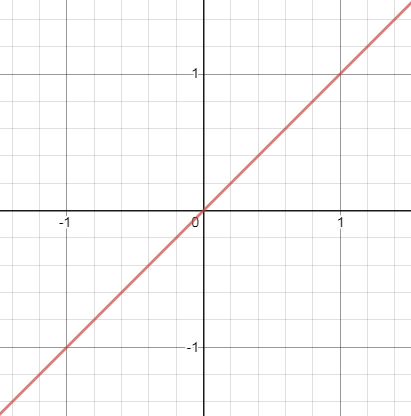
The problem with this activation is that it is not defined in a certain range. Applying this activation function in all the nodes makes it works like linear regression. The last layer of the Neural Network will work as a linear function of the first layer.
The second problem is that during gradient descent when we differentiate it, it has a constant output which is not good because during backpropagation the rate of change of error is constant which ruins the output and the logic of backpropagation.
Non-Linear Activation function
The non-linear linear activation functions are the activation functions that are mostly used in Neural Network. Some of the non-linear functions are:
1. Sigmoid Activation Function
Think about selecting an activation function between binary activation function and linear activation function, we would like to use the activation function similar to binary activation function for supervised learning but also remove its discontinuity and making it smooth. Sigmoid function is the activation function which is differential and continuous. The time to change from 0 to 1 is also very less which makes it better to classify things between two outputs.
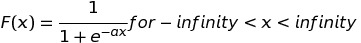
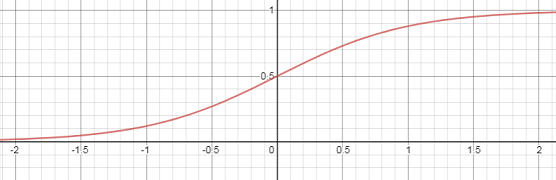
Observing the sigmoid function, we see that the slope of function decreases when there is an increase in the value of x so the gradient vanishes. This means the change in error decreases with respect to change in weight due to which the gradient does not perform well after a few iterations. So, we don't always get a perfect weight of neurons in a Neural Network.
2. Gaussian activation function
Let us suppose that we want to activate the neurons only for specific input. Then Gaussian activation function is a perfect differentiable and continuous function for it.
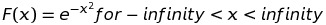
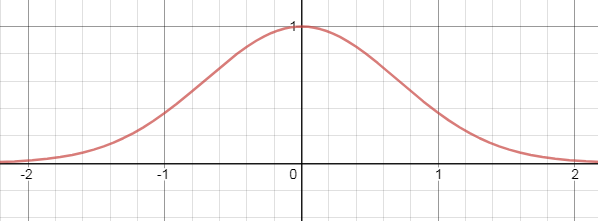
As we observe the graph, the slope of the graph decreases and becomes zero as the value increases, it too faces the problem of vanishing gradient.
3. Tanh Function
Tanh function is a similar function like sigmoid function. The only perk we will get using Tanh function is that the slope of function does not decrease quickly like sigmoid function. So the gradient does not vanish quickly.
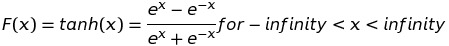
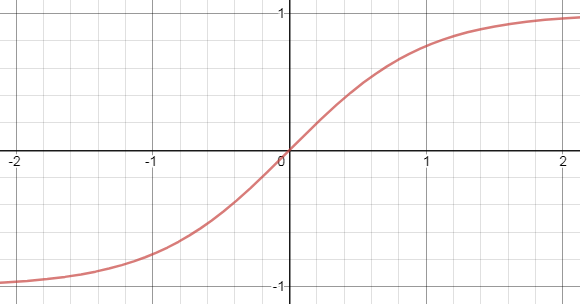
4. ReLU function
ReLU stands for the Rectified Linear Activation Unit. This is the most used activation function for hidden layers. We observe that the above non-linear activation functions do face the vanishing gradient problem. So, we can think of using a limited linear activation function only in hidden layers so that our gradient does perform well in the hidden layer at least. So, we use ReLU which returns the same output as output for positive values and zero for negative values.
F(x)=max(0,x) for -infinity<x<infinity
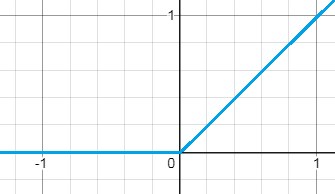
The problem with ReLU is that for negative input values, the output will always be zero. There will be no change in weights during gradient descent at all for negative value.
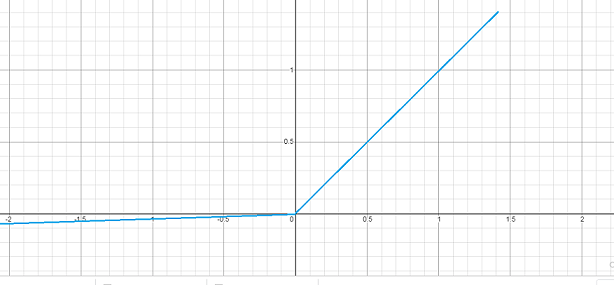
5. Leaky RELU function
To fix the problem of the ReLU activation function, for negative values in Leaky ReLU, we will leak the value of negative numbers slowly. We introduce a negative slope which is very small and speeds up the training. The output as compared to the negative input value is very less. Below is the equation of Leaky ReLU:
F(x)=0.01x for -infinty<x<=0
F(x)=x for 0<x<infinity
5. Softmax Activation Function
Leaky ReLU does solve the problem of hidden layers. But we still didn't get a perfect activation for the output layer. So, Softmax gives us the solution for the output layer activation layer.
To visualize the Softmax Activation function, suppose we want to identify an object to be banana, cucumber, or mango. So we get its color, size, thickness, shape and other features of the object. We calculated the probability of that object of banana, cucumber, and mango to be 0.7, 0.2 and 0.1 respectively. We choose the object having the highest probability which is banana.
The Softmax activation function calculates the probability of all the output units and activates the output node having the highest probability. Suppose there are k output nodes, the probability of the ith node is:
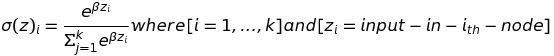
The sum of probability equals to one. Softmax activation is the most used activation function for the output layer.
When to use which Activation function in Neural Network
The use of a specific Activation function depends on the use-case. If we want to use a binary classifier, then the Sigmoid activation function should be used. Sigmoid activation function and Tanh activation function works terribly for the hidden layer. For hidden layers, ReLU or its better version leaky ReLU should be used. If we have a multiclass classifier then Softmax is the best-used activation function.
Most of the machine learning developers use a combination of two or more activation at different layers in the activation function. Though there are more activation functions known but these are the most used activation function used right now.
I hope we have got an idea about Activation functions and its types.
Thank you so much for your time.
Happy Machine Learning 🙂
Team AfterAcademy
Written by AfterAcademy Tech
Share this article and spread the knowledge
Read Similar Articles
AfterAcademy Tech
Mastering Backpropagation in Neural Network
In this blog, we are going to master the Backpropagation Algorithm used in Neural Network in Machine Learning. We will also cover the intuition behind it and it's derivation.

AfterAcademy Tech
What is a network and what are the nodes present in a network?
In this blog, we will mainly learn about a computer network and its node. We will also cover the classification, goals, and applications of a computer network.

AfterAcademy Tech
What is network topology and types of network topology?
In this blog, we will learn about various network topologies, their advantages and disadvantages in a computer network.

AfterAcademy Tech
What are Peer-to-Peer networks and Server-Based networks?
In this blog, we will learn about the types of network based on design, that are Peer-to-Peer, and Server-Based networks. We will also see the applications, advantages, and disadvantages of using these networks.
