What is Data independency?
AfterAcademy Tech
•
21 Mar 2020

The main purpose of the three levels of data abstraction is to achieve data independence. As the database changes and expands over time, it is very important that the changes in one level should not affect the data at other levels of the database. This would save time and cost required while changing the database. So, let's get started and learn more about data independence.
Data Independence
Data independence refers to the property of DBMS through which we can modify the schema definition at any level without changing the schema definition at any higher level. A database has three levels of abstraction as shown in the diagram below.
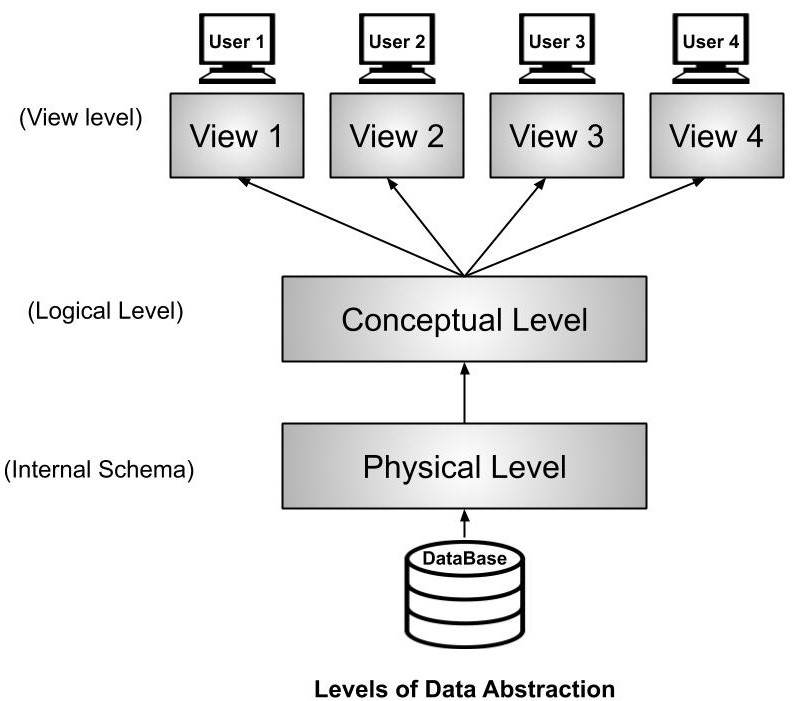
We have two levels of data independence that are defined on the basis of these three levels of abstraction.
- Physical Data Independence
- Logical Data Independence
Physical Data Independence
Physical Data Independence refers to the characteristic of changing the physical level without affecting the logical level or conceptual level. Using this property we can easily change the storage device of the database without affecting the logical schema.
Example: Suppose you want to replace the storage device form hard disk to SSD or magnetic tape then it should not affect the data stored at the logical level.
The changes in the physical level may include changes like:
- Using a new storage device like SSD, magnetic tape, hard disk, etc.
- Using a new data structure for storage.
- Using a different data access method or using an alternative file organization technique.
- Changing the location(like changing the drive) of the database.
Logical Data Independence
It refers to the characteristics of changing the logical level without affecting the external or view level. This also helps in separating the logical level from the view level. If we do any changes in the logical level then the user view of the data remains unaffected. The changes in the logical level are required whenever there is a change in the logical structure of the database.
The changes in the logical level may include:
- Changing the data definition.
- Adding, deleting, or updating any new attribute, entity or relationship in the database.
That’s it for this blog. Hope you learned something new today.
Do share this blog with your friends to spread the knowledge. Visit our YouTube channel for more content. You can read more blogs from here.
Keep Learning 🙂
Team AfterAcademy!
Written by AfterAcademy Tech
Share this article and spread the knowledge
Read Similar Articles
AfterAcademy Tech
What is Data Integrity?
In this blog, we are going to learn what is data integrity. We will also learn that why data integrity is important and how we can achieve it using various integrity constraints.

AfterAcademy Tech
Introduction to Data Structures
Data structures are widely used in every aspect of computer science. Data structures are the way of organizing and storing data in a computer so that it can be used efficiently. In this blog, we will look into data structures, its types, operations and applications.

AfterAcademy Tech
What is Data Model in DBMS and what are its types?
In this blog, we will learn about various data models present in DBMS. We will also learn about various types of data models present along with advantages and disadvantages of each model.

AfterAcademy Tech
Introduction to Heaps in Data Structures
Heap is a very useful data structure that every programmer should know well. The heap data structure is used in Heap Sort, Priority Queues. The understanding of heaps helps us to know about memory management. In this blog, we will discuss the structure, properties, and array implementation of heaps.