What is Data Abstraction in DBMS and what are its three levels?

Have you ever wondered how the same website has different views for different users? For example, a college website has a different view for student, faculty and the dean. A student will see the details of his/her attendance, homework, etc. While a faculty will see his/her class time-table and all information that is related to a faculty. We see only that much amount of data which is necessary and other data is hidden from us. So, what is this phenomenon called? Yes, you got it right. This phenomenon is called data abstraction. In this blog, we will learn about data abstraction and we will also see the three levels of abstraction in DBMS. So, let's get started.
Data Abstraction
Data Abstraction refers to the process of hiding irrelevant details from the user. So, what is the meaning of irrelevant details? Let's understand this with one example. Example: If we want to access any mail from our Gmail then we don't know where that data is physically stored i.e is the data present in India or USA or what data model has been used to store that data? We are not concerned about these things. We are only concerned with our email. So, information like these i.e. location of data and data models are irrelevant to us and in data abstraction, we do this only. Apart from the location of data and data models, there are other factors that we don't care of. We hide the unnecessary data from the user and this process of hiding unwanted data is called Data Abstraction.
There are mainly three levels of data abstraction and we divide it into three levels in order to achieve Data Independence . Data Independence means users and data should not directly interact with each other. The user should be at a different level and the data should be present at some other level. By doing so, Data Independence can be achieved. So, let's see in details what are these three levels of data abstraction:
- View Level
- Conceptual Level
- Physical Level
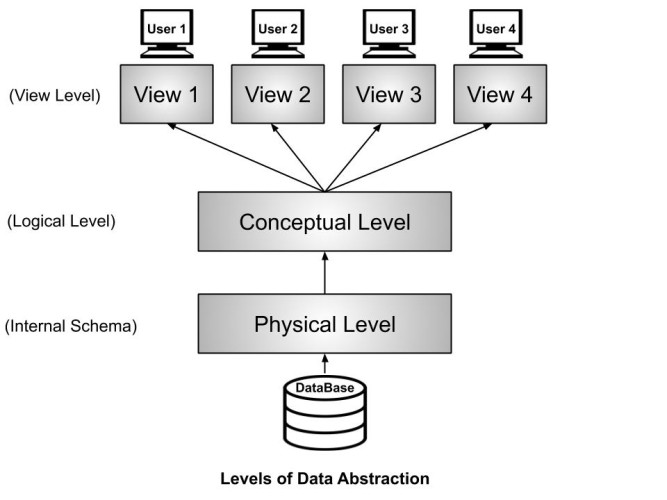
View Level or External Schema
This level tells the application about how the data should be shown to the user. Example: If we have a login-id and password in a university system, then as a student, we can view our marks, attendance, fee structure, etc. But the faculty of the university will have a different view. He will have options like salary, edit marks of a student, enter attendance of the students, etc. So, both the student and the faculty have a different view. By doing so, the security of the system also increases. In this example, the student can't edit his marks but the faculty who is authorized to edit the marks can edit the student's marks. Similarly, the dean of the college or university will have some more authorization and accordingly, he will has his view. So, different users will have a different view according to the authorization they have.
Conceptual Level or Logical Level
This level tells how the data is actually stored and structured. We have different data models by which we can store the data(You can read more about the different types of data model from here ). Example : Let us take an example where we use the relational model for storing the data. We have to store the data of a student, the columns in the student table will be student_name, age, mail_id, roll_no etc. We have to define all these at this level while we are creating the database. Though the data is stored in the database but the structure of the tables like the student table, teacher table, books table, etc are defined here in the conceptual level or logical level. Also, how the tables are related to each other are defined here. Overall, we can say that we are creating a blueprint of the data at the conceptual level.
Physical Level or Internal Schema
As the name suggests, the Physical level tells us that where the data is actually stored i.e. it tells the actual location of the data that is being stored by the user. The Database Administrators(DBA) decide that which data should be kept at which particular disk drive, how the data has to be fragmented, where it has to be stored etc. They decide if the data has to be centralized or distributed. Though we see the data in the form of tables at view level the data here is actually stored in the form of files only. It totally depends on the DBA, how he/she manages the database at the physical level.
So, the Data Abstraction provides us with a different view and help in achieving Data Independence. That's it for this blog.
Do share this blog with your friends to spread the knowledge. Visit our YouTube channel for more content. You can read more blogs from here .
Keep Learning :)
Team AfterAcademy!





